Ecrire des specs comme un seigneur (un article qui dénonce)
Sommaire
- From TagCo to Dubaï bébé
- Du plan de marquage au plan de démarquage
- Mais pourquoi écrire des specs correctement, c’est important ?
- Sur le fond : respect l’écosystème tech
- Sur la forme : ce qu’il ne faut pas faire => la spec “jeu_de_go.xls”
- Sur la forme : ce qu’il faut faire
- Exemples
- Le cas des templates / modules
- Et après ça ?
From TagCo to Dubaï bébé
La vie d’expert en webanalytics, c’est loin d’être simple : entre soirées mondaines avec des stars de la pop culture (Taylor Swift, JP Fanguin, Adrien Truffert…), dîners dans les plus grandes tables étoilées de la Capitale, et interviews dans les journaux people, nous oublions souvent que notre vie a démarré par des aspects beaucoup plus triviaux, et proches des Français. Et être proche des Français, ça commence, cela va vous surprendre, par écrire des spécifications techniques. Personne n’aime ça, beaucoup de gens traitent cette tâche parfois ingrate par-dessus la jambe, et pourtant, c’est bien ici que la crème de la crème de la webanalytics parvient à prouver sa valeur.
Bienvenue dans le monde terrible de Jira, Confluence, Redmine, et peut-être même Azure DevOps. Attachez vos ceintures, aujourd’hui, nous allons voir comment vous allez devenir un(e) orfèvre du dataLayer.push.
Du plan de marquage au plan de démarquage
Au commencement (de la webanalytics), en l’an de grâce -15 avant Google Tag Manager, les pionniers de la webanalytics devaient tout faire implémenter en dur. Eh oui, pour les petits jeunes qui débarquent, il existait un temps où changer un event label dans GA (voire dans Urchin pour ceux qui doivent désormais compter leurs trimestres avant la retraite) passait par un dev custom, et donc une mise en prod. Et bien sûr, à l’époque, pas de CI / CD, pas de microservices, pas de pipelines de tests auto, pas de staging : chaque déploiement avait le potentiel de faire tomber un site aussi rapidement que Neymar à l’approche d’une surface de réparation. Et autant dire qu’en ce temps, nous autres petites personnes de la webanalytics, nous devions être au taquet pour nous faire respecter.
Depuis, les TMS sont arrivés, et nous ont, en théorie, allégé le travail ; mais nul n’est censé ignorer que, aussi agnostique soit-elle, votre spec GTM (remplacez par l’outil de votre choix si vous êtes une personne audiacieuse qui travaille avec un outil concurrent) doit toutefois être écrite avec rigueur. Car, en toute logique, si on minimise la quantité de code dédiée aux tags de marketing, on doit être d’autant plus rigoureux. Moins, mais mieux.
Mais pourquoi écrire des specs correctement, c’est important ?
J’en ai déjà beaucoup parlé sur les Internets, que vous le vouliez ou non, une implémentation réussie, ça passe par une bonne collaboration avec l’équipe de dev. Et au risque de me fâcher avec mes confrères / consoeurs, il m’est arrivé trop souvent de tomber sur des plans de marquage existants qui avaient été pris un peu à la rigolade par les devs, voire sur des “specs” (air quotes très marquées) qui avaient été négociées “à la zob” dans un obscur canal Teams introuvable parce que… bah parce que Teams quoi, j’ai vraiment besoin de vous expliquer ?
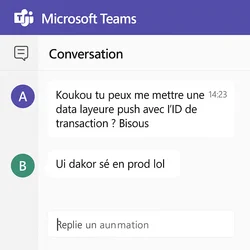
Notre exposé s’organisera donc en 3 points, comme ma disserte de philo au bac qui m’avait valu le 13/20 le plus volé de l’histoire :
- Sur le fond : qu’est-ce qui fait une bonne spec ? (on commence tranquille)
- Sur la forme : ce qu’il ne faut pas faire (ça va piquer, rien de personnel, dézo si vous vous sentez visé)
- Sur la forme : ce qu’il faut faire (réconciliation karmique instantanée)
Sur le fond : respect l’écosystème tech
C’est à mon sens ce qui fait défaut à la majorité des “mauvaises” specs que je vois passer : à aucun moment la personne qui les a écrites n’a pris la peine de comprendre quelles étaient les technos utilisées sur le site : quel CMS, quelle librairie CSS, quel pattern d’URL, quel système d’authentification…
Prenons un exemple simple, mais symptomatique de ce bordel : Rodrigue, notre web analyst débutant, et donc notre victime désignée aujourd’hui, a tapé “plan de marquage” sur le post LinkedIn d’un influenceur qui est prêt à partager à sa comu le plus gros banger sourcé auprès de 3000 experts en tracking (vue d’esprit). Ladite spec préconise de faire quelque chose comme ceci lorsqu’il s’agit de mesurer une “simple” page vue, et de la catégoriser :
dataLayer.push({
'event' : 'pageView',
'pageName' : 'Chaussettes Motif Zèbre - Taille 41', //Nom de la page, à renseigner par le développeur informatique
'pageCategory' : 'Détail produit', //Type de page, également à renseigner par la personne qui se charge des ordinateurs
'productType' : 'Chaussettes' //Eh ouais sans déconner c'est le type de produit, incroyable non ? Oui, toujours à réaliser par le codeur numérique
});Eh ben oui. Mais en fait non. Rien ne va ici. Intéressons nous par exemple à la notion de ‘pageName’ pour l’expliquer. Votre site est peut être géré server side (Symfony, Ruby on Rails, un truc étrange en Java…), auquel cas la page est chargée en un bloc, et appelle GTM à chaque fois. Ou alors, peut-être que l’on travaille sur une app Vue ou React, et que votre page vue correspondra à un changement de route, et dans ce cas il peut être intéressant de savoir si vous voulez exploiter ladite route. Et donc, selon le contexte, le “nom de page” peut être une notion tout à fait différente.
Cela vous paraît peut-être anecdotique, mais j’ai littéralement eu ce cas en travaillant pour un client dans le domaine de l’assurance, sur lequel je devais implémenter GA sur un parcours de souscription. Un truc long. Vraiment long. Long comme un tunnel d’assurance, vous voyez l’idée. Eh bien le tunnel en question, qui utilisait de la tech moderne et bien faite, était en réalité une grosse app React, où chaque étape du tunnel avait un nom technique (donc pas exploitable dans un rapport d’analyse), et un nom “fonctionnel” (celui qui était affiché sur l’UI). Et en l’occurrence, ces 2 infos étaient nécessaires, et indispensables.
La spec, réalisée par mes soins et donc absolument parfaite, ressemblait donc à ceci :
dataLayer.push({
'event' : 'routeLoad', //Plus cohérent, reflète la techno. Une route, c'est un vrai concept React
'routeTechName' : 'vehicle_api12', //Valeur renvoyée par l'API gérant le contenu. Nom technique super facile à récupérer côté front.
'routeUIName' : 'Choix du véhicule' //Valeur affichée sur la page, donc qui existe forcément dans le code.
});Bien sûr, ces infos ne sortent pas du chapeau, et il a fallu faire au préalable un call technique avec la front dev qui s’occupait de l’app React en question, mais qui a sans aucun problème pris le temps de m’expliquer les notions techniques sous-jacentes. Résultat : une spec ultra limpide et très facile à mettre en place pour elle, et surtout sans aucune ambiguïté technique.
Second exemple : s’inspirant du plan de marquage sus-mentionné récupéré sur Linkedin, Rodrigue veut aller mesurer la catégorie de produit lors d’un ajout panier, et va commettre ceci (admettons que nous soyons sur un site marchand) :
dataLayer.push({
'event' : 'addToCart',
'productID' : '123456789', //Remplir avec l'ID de produits lol, follow moi sur LinkedIn pour plus de posts en growth marketing et IA
})Non. Non. Et globalement encore non. Rodrigue, tu dois te reprendre. Et couper les notifications LinkedIn sur ton Apple Watch.
Une nouvelle fois, un exemple sera plus parlant : dans un passé récent où je travaillais pour un célèbre revendeur de croquettes pour animaux, subsistaient dans l’écosystème des specs qui avaient exactement cette tête de “wesh mets la catégorie de produit”. Sauf que chez le revendeur de croquettes en question, considérer l’ID de produit comme une information “simple” auprès des devs revenait à leur cracher au visage, insulter leur maman, et ensuite les piétiner avec des rangers à clous rouillés. Car, pour un produit vendu sur le site en question, l’ID produit pouvait être, entre autres :
- Le code EAN
- Le SKU
- Le code Magento (dans le cas où le produit était vendu en B2B)
- Le code issu de l’ERP
A savoir que dans notre affaire, les 4 informations étaient absolument cruciales et indispensables, mais pas pour les mêmes équipes. Et que donc, réalistement, ma profonde connaissance de l’écosystème m’avait fait écrire quelque chose comme ceci :
dataLayer.push({
'event' : 'addToCart',
'EANCode' : '123456789',
'SKU' : '654987321',
'magentoCode' : 'abcdefghi',
'erpCode' : '000aaabbb'
})Et là, vous allez me dire “oui mais une nouvelle fois tu fais preuve d’excès dans ta démarche. Il est bien évident qu’une telle situation génèrera une réunion constructive avec l’ensemble des parties prenantes de la Direction des Services informatiques, le coach Agile et les chefs de projets transverses”. Alors d’abord félicitations pour votre nouveau poste de directeur juridique, mais aussi et surtout, 2 contre arguments sérieux à ce genre d’affirmation :
- Si vous aviez en amont pris la peine de soulever le capot, vous n’auriez pas eu à faire une réunion avec un coach Agile. Personne ne veut fréquenter ces gens. Sauf peut-être d’autres coaches Agile. Est ce que quand 2 coaches Agile se rencontrent, c’est comme diviser par zéro ? Tant de questions.
- Il y a aussi tout à fait un monde, et celui-là est de loin beaucoup plus dangereux, où tout ceci va se dérouler de façon silencieuse (sans coach agile, donc), et où votre spec va passer de main en main, et tout simplement être traitée un peu à la légère. Et j’ai très sérieusement vu des agences se faire (à raison) virer parce qu’il avait fallu 6 mois pour comprendre que la spec n’avait pas été assez claire, et donc interprétée de façon différente par les 4 équipes les ayant implémentées. Et les dégâts avaient été considérables, avec des données venant in fine arroser un data lake ; et lorsque dans ledit data lake, des analystes sérieux (au sens des gens travaillant au département ℭ𝔬𝔫𝔱𝔯𝔬𝔩𝔢 𝔡𝔢 𝔤𝔢𝔰𝔱𝔦𝔬𝔫) se sont rendus compte que les identifiants produits n’étaient jamais les mêmes à cause de cette spec de sagouin, il est évident que la soufflante que s’est ramassée l’agence était d’au moins 8 sur l’échelle de Richter.
Bref, vous m’avez compris (j’espère, sinon je ne vois vraiment pas pourquoi vous êtes allé aussi loin sur cet article. Merci de fermer ce navigateur et d’avoir une vie), vous allez devoir à un moment donné sortir de votre cave et aller parler à des gens. Et si cela est bien évidemment surtout valable si vous travaillez pour de grosses entreprises, il reste tout à fait possible que même votre “petit” client qui gère son Prestashop dans son coin a en réalité un ERP de taille raisonnable (Odoo, à tout hasard), eh bien il va falloir utiliser son cerveau 10 minutes et comprendre comment tout ceci communique.
Et (aparté gratuit mais je fais ce que je veux c’est mon blog) je sais bien que certains d’entre vous facturent ce que j’appelle “à la pièce”, et ont leur fameux forfait magique à 997,97€ HT pour faire une implé GA4 / CAPI / TikTok / 2 cafés serrés, un des deux avec un nuage de lait / l’addition, et que le fait de devoir faire les efforts de sociabilisation sus-mentionnés grignote leur marge, et que peut-être même qu’à un moment ils vont devoir faire autre chose que du data layer standard, eh bien oui les amis, même s’il ne faut pas jeter le bébé avec l’eau du bain, dézo mais ça s’appelle de la gestion de projet et ça fait aussi partie du job.
En vrac, et de façon absolument pas exhaustive, voici dans les grandes lignes les familles d’outils qui touchent au front d’un site, et qui peuvent donc aller alimenter votre beau travail de tracking des interactions utilisateur :
- Référentiel produit (ERP, PIM, microservice à la limite de la sorcellerie codée en 1996 par un dev qui part à la retraite en juin prochain)
- Techno purement front (Vue, React)? Site généré côté serveur (Symfony, Laravel, Wordpress…) ? Techno hybride (CMS Headless) ?
- Techno d’authentification (OKTA, IAM, etc.)
- Techno de recherche (Algolia, Elastic, Solr ?)
- Techno de paiement (Stripe, Paypal, API SOAP du Crédit Agricole du Limousin ?)
Sur la forme : ce qu’il ne faut pas faire => la spec “jeu_de_go.xls”
Partant de ce constat, regardons maintenant ce que je considère être de mauvaises pratiques, mais cette fois en termes de forme.
Nous l’avons tous vu passer quelque part au moins une fois : ce fichier terrifiant, qui comprend en ligne toutes les pages du site, et en colonnes tous les attributs du data layer, avec à chaque fois la valeur que doit prendre un attribut sur une page donnée :
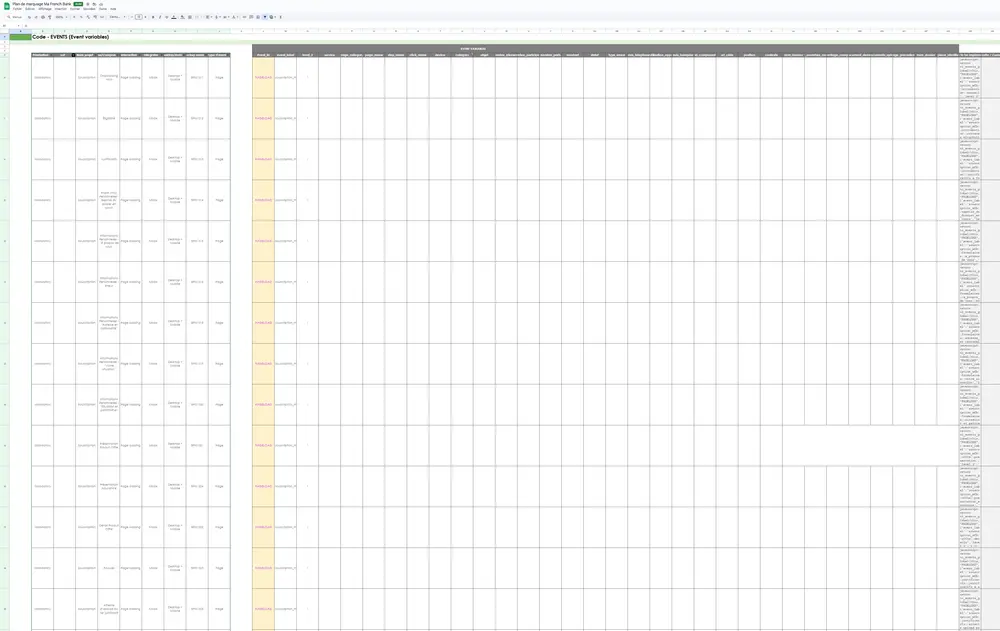
(Pour info, screenshot pris sur un écran de 49 pouces, avec un dézoom de 50%. Les Ophtalmos Me Détestent)
Ce genre de fichier terrifiant se finit en général avec quelques centaines de lignes, et (seulement) quelques dizaines de colonnes (tout le monde a une souris avec un scroll horizontal sous la main, c’est bien connu).
Je souhaite faire preuve d’empathie, car après tout je suis qu’amour et volupté, mais à quel moment est ce que ça a à ce point dérapé dans votre vie ? Vous pensez que le dev du site crafte, tel un petit artisan, chaque page à la main, et la dépose méticuleusement sur son Filezilla, en récitant un haïku à la gloire de Richard Stallman ? Désolé de vous décevoir, mais non : dans le cas où vous avez affaire à un dev consciencieux (je n’ai même pas envie de couvrir le cas contraire), il va prendre chaque cellule, et essayer de deviner ce que vous aviez derrière la tête au moment d’écrire cette spec, qui prend la logique technique de votre site, la piétine, asperge du kérosène dessus, puis l’attaque au lance-flammes. Il va ensuite essayer de comprendre comment les valeurs que vous souhaitez voir mises en place vont coller à la logique technique du site, ce qui finira souvent pas une énorme boucle switch…case ultra complexe à maintenir et très bancale.
Je tairai le nom de l’agence où cela est arrivé car je ne veux pas m’embrouiller avec Publicis, mais j’ai vu une telle spec facturée 14 000 € (hors taxes, faut pas déconner). Quatorze mille euros, vous avez bien lu. Et le pire dans l’histoire, c’est que le brave consultant qui avait commis ce document, en dépit de son TJM probablement astronomique, y avait réellement passé plusieurs jours.
Je me sens triste du coup, on passe à la suite.
Sur la forme : ce qu’il faut faire
Bon, maintenant que je me suis mis à dos la moitié de l’immense lectorat de ce blog (salut, on est 16, on rigole bien, et j’envoie GA4 en G111 sans consentement, lol), je vais tout de même essayer de me justifier.
En substance, peu importe l’outil que vous allez utiliser, ce qui compte, c’est que vous devez écrire du code.
L’intérêt d’avoir tout passé sur GTM est précisément que le data layer est une couche d’abstraction qui est faite pour être neutre, simple, et justement simple à spécifier. Le data layer est un simple array d’objets, docile, qui fait juste ce qu’on lui demande, et rien de plus. Un bon stagiaire, en somme.
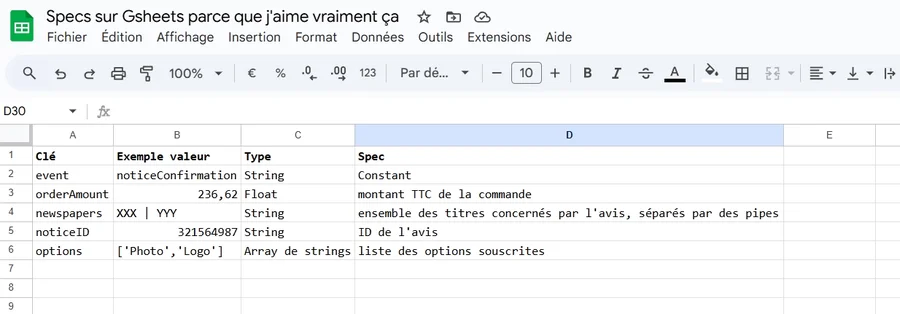
Il serait donc illogique, voire irrespectueux, pour ne pas dire criminel, que votre spec ressemble à autre chose que ceci (par exemple, si on travaille sur un site qui permet de créer une petite annonce) :
Au moment de la validation de l'annonce :
(window.dataLayer = window.dataLayer || []).push({
'event' : 'noticeConfirmation'//String : Constant
'noticeConfirmation' : {
'orderAmount' : 236.62,//Float : montant TTC de la commande
'newspapers' : "XXX | YYY",//String : ensemble des titres concernés par l'avis, séparés par des pipes
'noticeID' : '321564987',//String : ID de l'avis
'options' : ['Photo','Logo']//Array de strings : liste des options souscrites
}
});Ce type de syntaxe devrait grandement faciliter le travail du développeur qui travaillera sur l’intégration de votre beau plan de marquage : il n’a qu’à copier / coller le snippet dans son code, supprimer les commentaires, et les remplacer par la logique technique (ce pour quoi il est payé, au final). On peut par exemple imaginer que la valeur de ‘orderAmount’ sera récupérée depuis une variable JS quelconque qui sera de toute façon disponible au moment de l’envoi de la confirmation qui nous intéresse.
J’aime bien le fait d’indiquer le type, et la valeur attendue pour chacune des clés du DL, directement “inline”, mais si vous avez un cas particulier qui est un peu complexe, ou bien ou de nombreuses valeurs sont attendues, vous pouvez très bien inclure une liste exhaustive un peu plus bas dans votre document.
Note rapide sur le (window.dataLayer = window.dataLayer || []).push({ : je sais qu’en principe la syntaxe classique est la suivante …
window.dataLayer = window.dataLayer || [];
dataLayer.push({
///etc
)}…mais je préfère avoir tout sur une seule ligne, et syntaxiquement cela revient exactement au même. Que voulez-vous ? On ne s’invente pas esthète.
L’avantage de ce format de spec, c’est que vous pouvez facilement aller faire des plans de marquage assez conséquents sur une seule page. Si vous avez envie de “chapitrer” ceci, ou de faire plusieurs pages pour avoir des choses bien séparées, bien sûr pas de souci, il est tout à fait possible de faire une page pour les interactions e-commerce, une page pour les interactions sur les composants front, etc… C’est de toute façon un système modulaire et facilement adaptable d’un outil à l’autre, contrairement à ces monstruosités de specs sur des outils de tableur.
En complément, il est super facile de copier / coller ceci dans votre outil de ticketing préféré (Jira, Confluence, Asana…), plutôt que de mettre “la spec est le fichier .xls de 32 Mo en PJ du ticket, démerde toi avec ça mon gars, mdr”.
Ensuite, si écrire du Code JavaScript est quelque chose qui vous donne de l’urticaire, et qu’Excel / Google Sheet est votre allié indissociable parce que “ça va plus vite”, sachez que je vous juge énormément, mais que vous pouvez sans trop de problème donner ce type de chose a un LLM qui transformera ceci en une spec croquante et fondante :
Je ne commets pas l’affront de vous donner le prompt qui transforme ceci en un beau dataLayer.push, vous êtes de grandes personnes, je vous fais confiance.
Et donc, en termes d’outils, on se dit quoi ? Là aussi l’avantage est que cela marchera sur après n’importe quoi qui permet d’écrire du beau code bien formaté, c’est à dire à peu près n’importe quoi aujourd’hui :
- Évidemment Notion, je pense qu’il n’y a rien à ajouter, même votre grande tante Yvonne fait son journal intime dessus depuis 2016.
- Un bon gros fichier Markdown sur un repo Github fera très bien le job, et aura le mérite de pouvoir gérer le versionning au poil (on y revient plus bas).
- J’aime aussi beaucoup Gitbook, qui est un peu plus niche, mais vraiment spécialisé dans la doc. Souvent un peu overkill mais très plaisant à utiliser, et qui génère des specs d’une élégance rare.
- Je me suis même surpris, récemment, à redécouvrir Google Docs. Oui, vous avez bien lu : Google Docs, cet outil utilisé par plus personne sauf peut-être votre comptable, qui dispose désormais d’un élégant bloc “Code” qui permet d’avoir quelque chose de pas mal, en plus d’un mode “pageless” comme on les aime, d’un expand / collapse de menus… et bien sûr des options de commentaire / versions / collaboration de la suite Google qu’on adore tant (ou pas).
Ci-dessous un petit florilège des screenshots des outils sus-mentionnés :
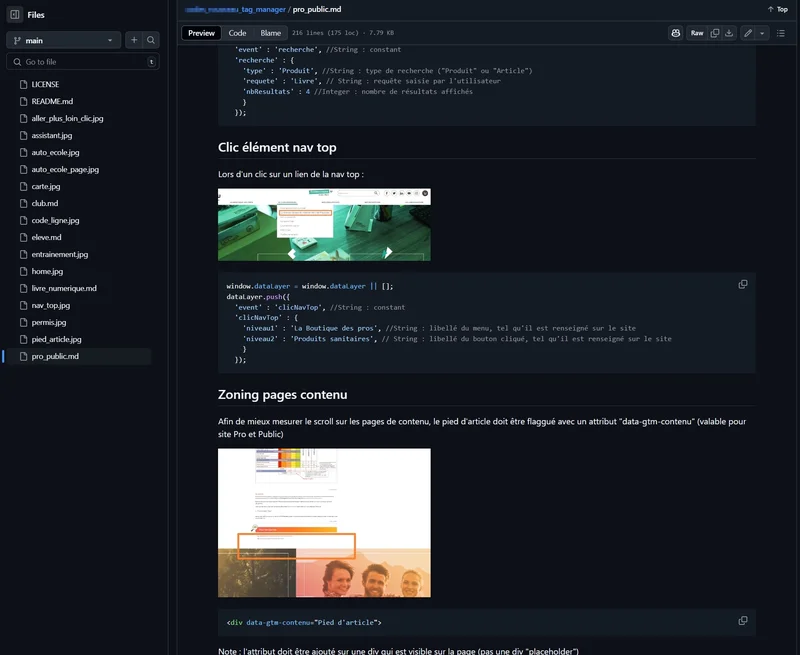
Exemples
Puisque je suis d’humeur généreuse, j’ai choisi de vous partager, de façon totalement gratuite et désintéressée (bon après achetez moi du consulting quand même please, faites pas les crevards) non pas un, mais bien deux exemples de specs, à peu près anonymisées et légèrement adaptées pour que vous compreniez le principe sur de vrais exemples (évidemment, j’ai supprimé les screenshots, vous devrez juste faire preuve d’un peu d’imagination, je ne vais pas non plus faire tout le boulot pour vous). Servez-vous, c’est cadeau de la maison :
La première est une spec issue d’un gros site éditorial, un beau Wordpress très custom et tout neuf. Elle comporte quelques particularités assez intéressantes :
- Sachant qu’à part GA il n’y avait pas grand-chose en termes de consentement, le (très bon) dev qui avait travaillé sur le sujet avait fait une CMP custom. On avait donc pu faire quelque chose de très minimaliste, mais suffisant pour mettre en place Consent Mode.
- Il y avait un système de monétisation assez poussé au lancement, avec un système d’abonnement “classique”, et un autre d’abonnement avec token, qui donnait donc des statuts articles assez poussés.
- Comme je l’ai dit plus haut, j’aime bien indiquer les valeurs possibles directement dans les commentaires, et on voit bien ici que pour quasi toutes les valeurs, c’est largement suffisant, et que ça fait quelque chose d’assez compact et lisible. Il n’y a qu’un cas où ça aurait été trop lourd, celui des Actions ‘mon compte’, puisque nous avions décidé de faire une spec générique pour tracker toutes les interactions utilisateur. Dans ce cas, pas de souci, je mets la liste exhaustive après le snippet, ça ne perturbe pas la lecture 👌.
- Je n’en ai pas parlé, mais j’utilise des flags HTML lorsque je veux tracker la visibilité d’un bloc (ici le pied d’article, qui permet de mesurer la lecture “engagée”). Utiliser un attribut data-xxx est une bonne pratique, car sémantiquement neutre. Et ça s’insère proprement dans mon doc de spec.
La seconde est très intéressante, car elle a une double complexité : il s’agit d’un site e-commerce, fait avec React. Sur le papier cela pourrait mettre en PLS notre bon vieux Rodrigue, mais dans la pratique, on voit que quand on se pose un peu sur le sujet, tout se passe plutôt bien :
- Pour ce qui est du e-commerce, les specs sont “à plat”, c’est à dire pas conformes à ce que Google attend pour GA4. C’est volontaire, j’y consacrerai bientôt un article.
- L’app React en question était connectée à un gros ERP bien complexe. J’avais dès que possible fait le job de comprendre comment les données issues de l’ERP étaient consommées par l’app, et j’avais pu récupérer un exemple du JSON récupéré par une page produit pour afficher les différents éléments de la page. Du coup, hyper facile de faire une spec en disant que l’on utilise quelque chose comme le “price.default.original_value_taxed” du JSON, puisque ça a été validé en amont, et du coup, c’est une formalité côté dev. Et même pour faire valider ceci par quelqu’un “du métier” comme on dit dans le monde de l’agilité, c’était une formalité, car il connaissait sur le bout des doigts toute cette complexité issue des données de l’ERP.
- Ici, on utilisait Axeptio comme CMP, donc bien sûr on inclut le snippet dans la spec, pourquoi se priver ?
- Le site était fait via une app React, mais lorsqu’il y avait un login toute l’app était rechargée (via un CMS qui s’appelle “Locomotive”), donc il fallait gérer ce cas spécifique (et fondamental), avec un data layer “server” qui était l’exception, mais une exception très importante.
Donc, bref, servez vous et inspirez vous librement (ou pas) de ceci, mais par contre, je vous vois venir : le premier qui chope ça et le met sur LinkedIn en “Le Template E-Commerce Qui Vous Permettra De Scaler Votre Agence de SMMA”, je le chope et je lui pète les genoux (oui je suis sur mon blog, je peux proférer des menaces physiques, il n’y a pas d’algo pour me censurer).
J’espère que vous avez compris que la spec miracle n’existe pas, et que tout mon point est bien de vous faire comprendre que tout ceci résulte d’un vrai process (pas si long que ça) de compréhension du site sur lequel vous travaillez. Et je compte sur vous pour plutôt utiliser ces exemples pour comprendre la méthodo qu’il y a derrière, et la “due diligence” technique, qui n’est franchement pas si compliquée que ça, et a fait gagner de précieuses heures sur les 2 projets.
Le cas des templates / modules
Je pense que cela mériterait un article à part entière, mais il est tout à fait possible (et même souvent souhaitable) que, lorsque vous travaillez sur un site qui utilise un CMS “courant” du marché, vous implémentiez GTM non pas via un développement “sur mesure”, mais via des plugins / modules. Voici 3 exemples de modules de qualité, que j’ai régulièrement utilisés :
Je trouve toujours marrant d’entendre certaines personnes qui considèrent que l’utilisation de tels modules est un sacrilège, parfois ignorent même leur existence, et ne savent faire que de la spec custom. J’ai aussi vu l’autre extrême, où certaines personnes ne posaient même pas la question, et partaient directement sur leur plugin préféré.
La réalité, c’est que, comme d’habitude, le contexte est clé : très souvent, ces plugins seront vos meilleurs alliés, mais il faut soigneusement savoir si le Magento / Prestashop sur lequel vous travaillez n’est pas trop “tordu” et permettra d’exploiter ces plugins nativement.
Et quoi qu’il arrive, quel que soit le site, il faut toujours a minima proposer l’alternative, et expliquer l’intérêt de l’option dev custom vs plugin (un peu comme server side on premise vs Stape vs AddingWell, mais on y reviendra un jour aussi).
Il y a beaucoup de choses à dire sur ce sujet, que je creuserai peut-être dans un article dédié.
Et donc, pour revenir à notre sujet de specs / documentation, chillax relax, on peut s’en passer, la plupart des extensions disposant même d’une doc intégrée.
Et après ça ?
Voilà. C’est fini. J’espère que vous avez trouvé ça bien. Vous avez peut-être trouvé qu’aller aussi loin sur le sujet relève de la démence mentale avancée. Peut-être que cet article va changer votre vie et que l’écriture de spec deviendra désormais un rituel sacré de votre morning routine. Ou alors peut-être que vous êtes entre les deux, sachant que vous êtes arrivé(e) au bout de cet article, c’est déjà pas mal.
Si ça vous a plu, vous pouvez laisser un commentaire bah non je suis encore trop nul pour installer un beau module de commentaires sur ce site, mais ça viendra. Allez liker le post que je ferai sans doute sur LinkedIn pour relayer ceci, envoyez-moi des messages par recommandé avec accusé de réception, ou juste parlez-en à vos amis ; s’ils ont de l’argent et veulent acheter une prestation de webanalytics c’est mieux, mais après je juge pas j’aime aussi bien les gens désemparés.
A bientôt !
*Aucun Rodrigue véritable n’a été blessé au cours de l’écriture de cet article